
The Future of AI Detection: Trends in Deepfake, Voice, and Generative Content Protection
The AI generated content explosion
The synthetic-content boom is not happening simply because models are getting better. It is happening because they are getting cheaper, faster, and far more available. Stanford’s 2025 AI Index reports that the inference cost for a system performing at the level of GPT-3.5 fell by more than 280-fold between November 2022 and October 2024; the same report says generative AI attracted $33.9 billion in global private investment in 2024, while 78% of organizations reported using AI in 2024, up sharply from the year before. At the same time, NIST’s synthetic-content guidance frames the challenge across text, images, audio, and video, and treats authenticity, provenance, watermarking, detection, and ongoing maintenance as one connected trust problem rather than a single-model classification task.
That shift matters because the frontline problem is no longer spotting comically bad fakes. It is defending digital trust when good-enough synthetic content lands in a payment flow, a courtroom filing, a media feed, a hiring process, or a customer-support interaction. The FBI’s 2025 Internet Crime Report release says AI-related complaints cost Americans nearly $893 million and explicitly notes the use of fake social profiles, voice clones, identification documents, and believable videos of public figures or loved ones. FinCEN, for its part, warned in late 2024 that suspicious activity reports involving suspected deepfake media had risen across 2023 and 2024, especially in schemes targeting financial institutions and customers. In other words: AI detection is becoming less like a niche content-moderation add-on and more like core cybersecurity, fraud, and trust infrastructure.
Deepfakes have moved from artifacts to interactive avatars
Early deepfakes were often exposed by the very thing that made them fascinating: visible artifacts. Odd facial blending, broken lighting, unnatural eye behavior, weak temporal consistency, poor lip synchronization. The research literature shows just how quickly that era is fading. A major 2025 survey on facial deepfake detection describes the field’s move from single-modal approaches toward multimodal analysis, and specifically highlights the transition from GAN-based fakes to diffusion-driven deepfakes, which are harder to catch because of their greater realism and robustness. A 2025 review of AI-created visual content makes the same broad point: visual synthesis and visual detection are now moving in lockstep, with generation quality rising fast enough to keep stressing detector generalization.
The next stage is more unsettling. It is not just “fake video,” but live, reactive, conversational presence. Research systems already point in that direction: LivePortrait reports portrait animation at 12.8 milliseconds on an RTX 4090; Livatar describes real-time talking-head generation at 141 FPS with 0.17-second end-to-end latency; and Avatar Forcing focuses explicitly on real-time interactive head-avatar generation for natural conversation. This is why real-time impersonation during calls is no longer theoretical. In a 2025 advisory, Singapore police described a case in which a victim joined a Zoom call populated by deepfake impersonations of supposed colleagues and transferred more than US$499,000. The deepfake threat has evolved from forged appearance to forged participation.
That is also why the future threat model extends well beyond static celebrity hoaxes. It now includes fully interactive AI avatars, synthetic spokespeople, virtual employees, “digital humans,” and persistent brand-safe characters that can respond in real time. China’s 2026 draft rules on digital humans, as reported by Reuters, underscore how serious policymakers already regard this category: the draft would require labelling, restrict unauthorized use of personal data and likeness, and ban use of digital humans to bypass identity verification. The regulatory language is catching up because the underlying capability is already here.
Voice cloning is becoming a primary fraud vector
Voice is turning into one of the most dangerous synthetic-media surfaces because it combines low collection cost with high emotional authority. The FTC has warned for years that a scammer can clone a loved one’s voice from a short clip gathered online, then use that clone in a family-emergency or extortion-style scam. That warning has aged disturbingly well. The FCC responded by ruling in 2024 that AI-generated voices in robocalls count as “artificial” under existing law, making unlawful robocalls that use cloned voices illegal under the Telephone Consumer Protection Act unless the caller has appropriate consent. When regulators move that fast, it usually means the abuse pattern has already stopped being fringe.
The future of voice detection will not be won by a single spectral classifier. Benchmarks are already showing why. The USENIX Security 2025 paper VoiceWukong evaluated 12 advanced deepfake voice detectors against English and Chinese samples produced by commercial and open models; most detectors had equal error rates above 20%, and even the best-performing detector was dramatically worse than on its original benchmark. The same study found that humans were badly fooled by the hardest voice fakes, with false acceptance rates above 82% in both languages on the most deceptive samples. So the next layer of defense is becoming more forensic and more behavioral at once: segmental speech-feature analysis tied to human articulation, breath-pattern analysis, acoustic fingerprinting, and eventually speaker-specific behavioral baselines. Research in 2025 and 2026 increasingly points toward interpretable cues such as segmental speech sounds and breathing patterns because those may be harder for speech generators to mimic consistently under compression, translation, clipping, replay, and style transfer.
And the attack surface is broad. Voice cloning can support CEO impersonation, fraudulent approvals, tech-support deception, voter suppression, social-engineering escalation, and disinformation. The FCC linked AI voice abuse directly to election misinformation in the Biden robocall case; the FBI now groups voice clones alongside fake videos, fake profiles, and fake documents in its public scam warnings. In practice, organizations should assume that if a workflow depends on a human voice sounding familiar, that workflow now needs technical verification and policy friction.
Generative fraud now includes documents, identities, and evidence
One of the biggest strategic mistakes organizations still make is treating “AI detection” as mostly an image-and-video problem. It is not. FinCEN’s 2024 alert warned that financial institutions were seeing schemes in which criminals altered or created fraudulent identity documents to bypass identity verification and authentication, and the Alan Turing Institute’s 2025 report on digital public infrastructure argues that synthetic identities and deepfake-enabled credential fraud are becoming systemic threats across banking, healthcare, and national identity programs. The Federal Reserve continues to describe synthetic identity fraud as the fastest-growing type of financial crime in the United States. Fraudsters are no longer just faking faces. They are fabricating persons, histories, supporting evidence, and transaction context.
That broader fraud trend now covers fake invoices, fake receipts, fake onboarding packages, fake bank statements, AI-generated social profiles, and synthetic supporting evidence. ESMA’s 2026 publication on online financial frauds in an AI world warns that scammers use AI to create convincing fake bank websites, order confirmations, and invoices by mimicking the branding, tone, and style of real firms. The FBI says AI-related scams now involve fake social profiles and identification documents. And the National Center for State Courts warns that AI-generated videos, fake documents, and fabricated screenshots are already a trust threat for courts, where even authentic evidence can be undermined by the growing plausibility of synthetic alternatives. This is where the stakes get very real: once every PDF, screenshot, audio clip, and selfie can be generated or altered convincingly, “looks plausible” stops being evidence.
The legal and institutional consequences are only starting to surface. NCSC describes one of the first known cases of deepfake evidence being submitted as purportedly authentic testimony, and notes a broader pattern in which fabricated AI-generated materials can erode public trust in judicial fairness. The deeper problem is not only fake evidence entering the record, but real evidence becoming easier to dismiss as fake. That is the “deepfake defense” problem in another form. It turns uncertainty itself into a weapon.
The next era is authenticity verification, not binary detection
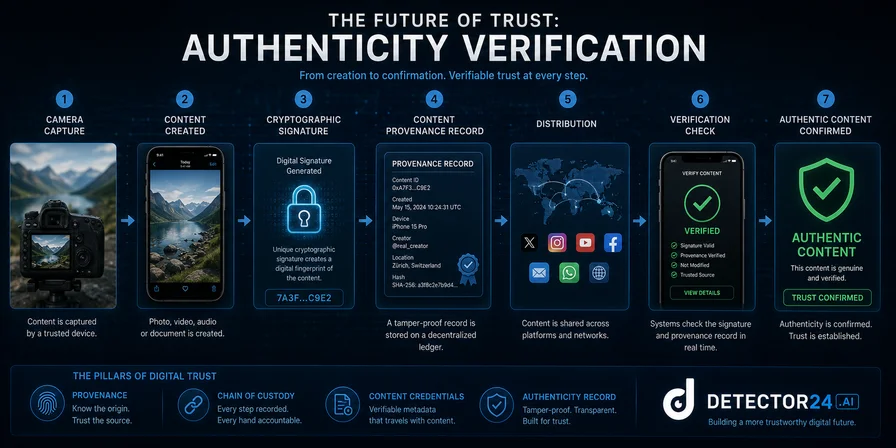
The most important long-term trend is philosophical before it is technical: the center of gravity is moving from “detect whether this is fake” to “verify whether this is authentic.” NIST explicitly distinguishes provenance data tracking from synthetic-content detection, and treats both as separate but complementary parts of digital-content transparency. C2PA exists for exactly this reason. Its standard is designed to establish the origin and edit history of digital media in a secure, tamper-evident, interoperable way. That distinction sounds subtle, but it changes the operational question. Instead of chasing every possible manipulation after the fact, organizations can increasingly demand evidence of origin, authorship, and chain of custody at creation time.
That future is already visible in hardware and publishing workflows. Leica introduced the first camera with built-in Content Credentials; Sony added in-camera digital signatures and C2PA support; Nikon rolled out secure Content Credentials on select cameras; and Canon launched a C2PA-compliant authenticity imaging system for news organizations in 2026, built around provenance records, certificates, and trusted timestamps. These are not “detectors” in the classic sense. They are authenticity systems. They create signed records at the point of capture and preserve them through editing and distribution. That matters because, operationally, proving signed origin is often easier than universally proving manipulation. That sentence is an inference from current standards and deployments rather than a settled theorem, but the direction is hard to miss. Provenance scales by recording what happened upstream; passive detection has to infer what may have happened downstream.
Still, provenance is not a silver bullet. C2PA itself acknowledges the metadata-stripping problem and points to watermarking and fingerprinting as ways to rediscover or rebind credentials when manifests are separated from files. NIST warns that watermarks can be removed and metadata can be stripped, while the European Parliament has noted serious technical limitations in current watermarking approaches, especially around robustness and implementation. Adoption is also inconsistent across platforms, creators, and devices. So the right mental model is not “provenance replaces detection.” It is “provenance will increasingly anchor detection.” The trust stack is converging, not consolidating.
Real-time, multi-layered AI detection tools will define the next stack

The same pattern appears everywhere in the research. Generalization is hard. Really hard. Deepfake-Eval-2024 found that open-source state-of-the-art deepfake detectors drop precipitously when tested on in-the-wild 2024 deepfakes gathered from social media and live users. VoiceWukong found equally painful degradation in audio deepfake detection. The ACL survey on LLM-generated text detection highlights out-of-distribution problems, attack surfaces, weak evaluation practices, and the difficulty of reliable real-world use. So the future of AI detection will not be a magical universal classifier that returns one authoritative answer. By 2026, the stack is becoming multi-layered, and detection tools will have to evolve rapidly as ai models keep changing. It will be a coordinated system that accumulates evidence from multiple weak but useful signals. For ai generated text, modern content detectors analyze text for statistical patterns such as perplexity and burstiness. In practice, ai detection tools combine feature-based methods that assess specific text characteristics with model-based methods that evaluate text holistically for accuracy.
That is why the strongest technical trends now point toward multi-model analysis, multimodal fusion, continual adaptation, and behavior-aware verification. AAAI 2025 introduced a multimodal deepfake detector that exploits multiple foundation models and fuses aligned audio-visual cues. New benchmarks such as DeepfakeBench-MM are being built specifically to test multimodal detectors across standardized pipelines. Continual-learning work in 2025 reframed deepfake detection as a chronological adaptation problem spanning years of generator change and found that, without ongoing retraining, generalization to future generators remains near-random; ai detectors often lag behind new generation systems, and even minor edits can cut accuracy to 42%, creating an arms race with generative systems. Meanwhile, real-time defenses are becoming more interactive and less passive: challenge-response methods for live video, gaze-based deepfake detection in dyadic calls, and increasingly explainable behavior-aware models. The core takeaway is simple: the future is not a single detection score, but layers of analysis working together. Future ai detection models will likely score content on a spectrum, including ai assisted cases, while detection models improve toward zero-shot detection of unseen generators. Provenance signals. Generator fingerprints. Audio-visual consistency. Presentation-attack detection. Injection-attack detection. Behavioral biometrics. Workflow context. Analysis of multiple inputs for anomalies. Subtle latent features. Human escalation.
That multi-layer model also explains why real-time detection is likely to become standard first in a handful of industries rather than everywhere at once. Financial services, remote identity verification, social platforms, government service portals, courts, journalism, and marketplaces all have one thing in common: they rely on rapid decisions made from user-submitted media or remote human interactions. In those environments, latency is part of the threat model. If the deepfake arrives during a live call or in a just-in-time claims flow, a detector that works an hour later may be operationally irrelevant.
Regulation, standards, and provenance are shaping the market
Policy is no longer waiting on perfect science. In Europe, the AI Act’s Article 50 creates transparency obligations for providers and deployers of certain AI systems, including duties around marking AI-generated or manipulated content in machine-readable form and labelling deepfakes and certain public-interest AI text. The European Commission has already launched a Code of Practice on marking and labelling AI-generated content and published draft guidelines on the implementation of these transparency obligations. That matters because it transforms authenticity from a voluntary trust feature into a looming compliance requirement.
There is, however, one important timing caveat. Official Commission pages still say the transparency obligations will apply from 2 August 2026, but Reuters reported in May 2026 that EU lawmakers and member states reached a provisional deal that would delay mandatory AI-content watermarking until December 2026. Until that is finalized and reflected consistently across official materials, compliance teams should treat the direction of travel as settled but the exact enforcement calendar as fluid. Outside the EU, China moved faster and more explicitly: its 2025 Measures for Labeling AI-Generated Synthetic Content require both explicit and implicit labels for AI-generated content across text, images, audio, video, and virtual scenes, with effect from 1 September 2025.
In the United States, regulation is arriving through a mixture of sector rules, enforcement, and state law rather than one single AI statute. The FCC has already used existing telecom law against cloned-voice robocalls. NCSL’s June 2026 summary says 30 states have enacted laws regulating deepfakes in political messaging, often through disclosure or prohibition rules, and some states now require metadata disclosures as well. Meanwhile, standards bodies are building the technical scaffolding that procurement teams will eventually rely on: ISO published a new framework in 2026 for testing and reporting biometric deepfake attack detection mechanisms, and FIDO’s face verification certification program includes liveness assurance against deepfakes, spoofs, and threat actors. The result is a market where compliance, testing, and security architecture are converging.
How organizations should prepare now
The practical question is not whether perfect detection exists. It does not. NIST says plainly that there is no silver bullet and that many technical approaches may still be years away from widespread mobile deployment. ENISA warns that remote identity proofing now has to account not only for presentation attacks, but also for digital injection attacks and new deepfake-era threat patterns. Courts, regulators, and law-enforcement bodies are already treating synthetic media as an active operational risk. So the organizations that will fare best are not the ones waiting for certainty. They are the ones building layered trust controls now.
- Screen across modalities, not channels. Do not separate image fraud, video fraud, audio fraud, and document fraud into isolated control towers. Build a unified screening layer that combines passive forensic checks, provenance discovery, metadata analysis, and context-based anomaly scoring for all user-submitted content and high-risk workflows. Mixed human created content is becoming the norm online, and 71.2% of new webpages will blend AI and human authorship by 2025. That is where the threat is headed, and the technical literature is already following it.
- Upgrade remote onboarding and verification flows. For KYC, KYB, AML, and remote identity verification programs, liveness alone is no longer enough if it ignores digital injection. Controls should include presentation-attack detection, replay defense, injection-attack detection, and testing against deepfake-class attack instruments. ENISA, FIDO, and ISO are all moving in that direction.
- Demand authenticity where authenticity matters. In journalism, claims handling, investigations, executive approvals, and legal evidence intake, require signed origin records and preserve chain of custody. If a workflow depends on trust, start capturing provenance at creation time rather than asking downstream reviewers to guess.
- Train people for synthetic-pressure attacks. Employees should know that a familiar voice, familiar face, or plausible screenshot is no longer proof. Executive callback policies, code words for emergency requests, dual authorization for unusual fund movements, and “pause and verify” drills are now basic controls, not overreactions.
- Treat AI detection as governance, not gadgetry. Assign owners. Define escalation paths. Test detectors continuously against new generators. AI detection tools vary widely by vendor and can return inconsistent outcomes. They also produce false positives and false negatives, so they should never be the sole basis for consequential decisions or for someone being incorrectly accused. In higher education, some institutions have already rejected detector-only workflows because of reliability concerns. Uploading student work into detection systems can raise FERPA-style privacy issues, and compliance teams are increasingly folding these controls into broader risk-management frameworks. Track emerging legal obligations. Set evidentiary rules for what counts as sufficient authenticity in your environment. Otherwise every deepfake incident becomes an improvised argument between security, fraud, legal, and communications.
The hard truth is this: hybrid authorship is becoming normal, so systems must distinguish human written content, AI generated writing, and AI assistance with care. It means trust becomes engineered. The next decade of AI detection will be defined less by one perfect detector and more by authenticity systems, provenance records, multimodal analysis, liveness and behavioral checks, and disciplined response workflows. Organizations that invest early will be better placed to prevent fraud, preserve trust, and meet tightening regulatory expectations. The question is no longer whether synthetic content will touch your business. It is whether, when it does, you will know what to trust. Open questions remain around final EU timing, platform-level adoption of provenance signals, and the long-run robustness of watermarking under adversarial removal. None of those uncertainties change the direction of travel.
Want to learn more?
Explore our other articles and stay up to date with the latest in AI detection and content moderation.
Browse all articles