
AI Detector for Educators and Publishers: Ensuring Authentic Content
Why authenticity is harder now—and why it matters
Generative AI has lowered the “cost of fluency” to near zero. A student can produce a passable essay in minutes; a content team can publish hundreds of pages in a day; a bad actor can flood platforms with synthetic reviews, comments, or pseudo-reporting. The result is not simply “more text.” It is more plausible text—material that looks finished even when the thinking, sourcing, and accountability underneath are missing.
With the rise of artificial intelligence in content creation, the need for reliable ai detector tools to verify originality has become essential for maintaining authenticity, quality, and transparency across industries.
Authenticity matters differently depending on the context, and that distinction is crucial if you want AI detection to function as decision support rather than a “gotcha.”
In education, authenticity is tied to learning outcomes: whether students practiced the skill you meant to assess, built conceptual understanding, and can explain their reasoning. AI detectors analyze written content to identify whether it was created by a human or generated by artificial intelligence, helping students ensure their work meets academic integrity standards before submission. When trust breaks, assessment stops measuring learning and starts measuring access to tools or willingness to game them—an equity problem as much as an integrity problem.
In publishing—especially news, scholarly, and other credibility-sensitive domains—authenticity is tied to brand trust, editorial standards, and accountability. AI detection tools are used by publishers and content creators to verify originality and promote transparency. Readers do not just want “human-written” prose; they want accuracy, sourcing, and transparent editorial responsibility. That’s why major editorial policies treat generative-AI output as unvetted source material that still needs human judgment, standards-based verification, and clear disclosure when AI plays a substantial role.
The practical goal, then, is not “ban AI.” It’s to clarify what’s acceptable, define what counts as misconduct or policy violation, and design workflows that protect integrity while minimizing wrongful accusations and avoidable disputes. Many publishers and standards bodies explicitly allow some forms of AI assistance—typically with disclosure and with humans retaining full responsibility—because a blanket ban is hard to enforce and often misaligned with real-world practice. Using AI responsibly and integrating AI detection into the writing process helps maintain trust and accountability in both educational and publishing environments.
What AI detection is, in plain language
AI text detection tools generally do not “detect the presence of AI” the way a metal detector detects metal. Most tools instead estimate whether a piece of writing resembles the model’s learned patterns of machine-generated text. These ai detectors work by leveraging machine learning models trained on large datasets of both AI- and human-written text to recognize patterns that distinguish the two. That’s why credible guidance frames detection output as probabilistic. It can inform review, but it cannot serve as definitive proof of authorship on its own.
A concrete example is Detector24’s AI-generated text detection model page, which states plainly that it provides “probability-based AI detection, not definitive proof,” and that “high AI probability suggests further investigation, not proof of misconduct.” It also explicitly recommends human review and warns against using the result as a final judgment in high-stakes decisions.
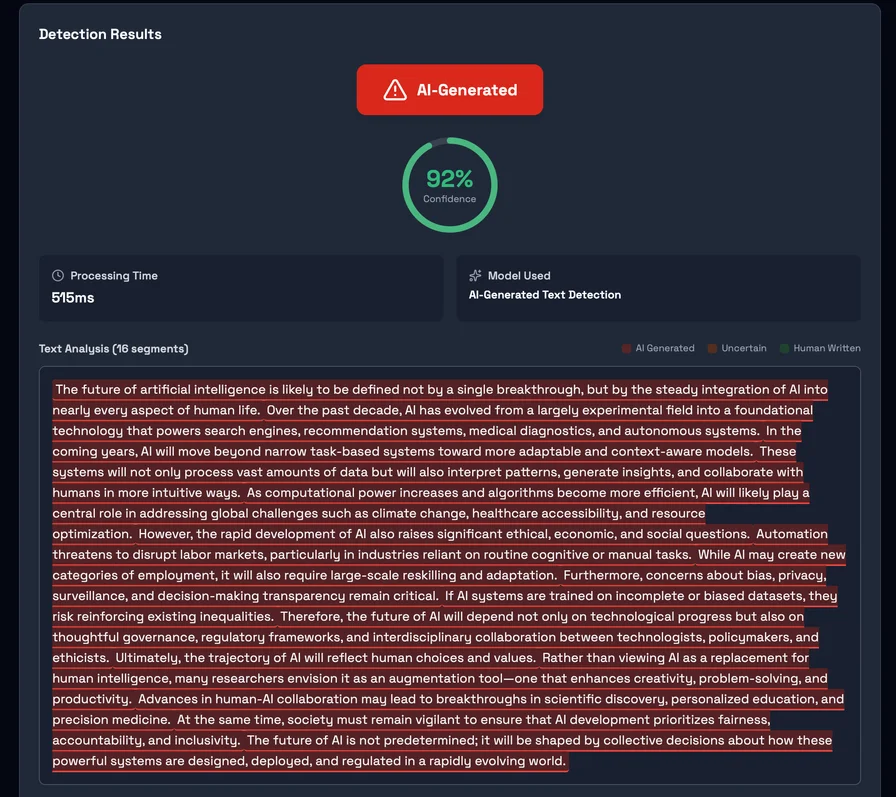
Detection tools can still be useful—especially when they provide granular signals that help triage and focus human attention. For instance, Detector24 describes “chunk-level analysis” (segmenting longer texts and scoring each chunk) and defines an internal “high-risk” threshold for chunks at or above an 80% AI probability. For the most accurate results, it is recommended to analyze your entire text at once rather than in smaller sections, as text length can affect the effectiveness and accuracy of AI detection. In practice, features like segment scoring can help reviewers ask a more precise question: Which passages look machine-like, and why? Typically, users paste their entire text into the ai detector tool, click a 'Detect AI' button to analyze text, and receive results with flagged phrases for review. To use an AI detector effectively, users should input their entire text and ensure it meets the minimum word count requirement, typically around 80 words.
After receiving the AI detection results, it is important to review any highlighted or flagged phrases to identify parts of the text that may be AI-generated or AI-refined.
The bigger research landscape reinforces the same theme: detection is an evolving technical contest, not a settled capability. The National Institute of Standards and Technology runs evaluations of “generators” and “discriminators” (detectors) because performance varies across models, domains, and time; some generators can deceive many discriminators, and some discriminators do well against most generators—no single detector is universally reliable.
Even OpenAI—which has built leading language models—has publicly stated that it is “impossible to reliably detect all AI-written text,” warned that classifiers should not be used as primary decision tools, and noted that AI text can be edited to evade detection.
The benefits of AI detection for educators and publishers
AI detection has become an essential asset for educators and publishers striving to maintain academic integrity and ensure the authenticity of written content. For educators, the ability to quickly and accurately identify AI-generated text in students’ work is crucial for upholding standards of original thinking and genuine learning. By leveraging advanced detection tools, teachers can confidently verify that assignments reflect students’ own understanding, reducing the risk of unintentional plagiarism and reinforcing the value of human written content in the classroom.
Publishers, on the other hand, face the challenge of safeguarding the credibility of their publications in an era where ai generated content can be produced at scale. AI detection enables editorial teams to screen submissions for ai generated text, ensuring that only authentic, human written content makes it to publication. This not only protects the reputation of the publication but also reassures readers that the information they consume is trustworthy and original.
Moreover, detection tools streamline the review process, allowing both educators and publishers to address potential issues with ai generated material efficiently. By flagging suspicious content early, these tools save valuable time and resources, enabling a more focused review of flagged passages and supporting a workflow that prioritizes quality and integrity. Ultimately, the use of ai detection fosters an environment where original writing is recognized and valued, helping institutions and organizations maintain high standards in the face of rapidly advancing ai generated content.
Where AI detectors fail: false positives, false negatives, and fairness in ai generated content
The two failure modes that matter most operationally are false positives (human text flagged as AI) and false negatives (AI text that passes as human). Both are unavoidable in current systems—but their cost differs by context. A false positive in a classroom can trigger disciplinary action, distress, and reputational damage; a false negative in publishing can allow low-quality or deceptive content to ship under your brand. No AI detector is 100% accurate, and results should not be solely relied upon to determine if content was AI-generated.
False positives have been repeatedly documented as a fairness risk, especially for non-native English writers. A peer-reviewed analysis of “GPT detectors” found that when seven widely used detectors were tested, they misclassified TOEFL essays written by non-native English speakers at an average false-positive rate of 61.3%, while showing near-perfect performance on a comparison set of U.S. eighth-grade essays. The authors link this disparity to how detectors often operationalize “perplexity” (how predictable the next word is), which can correlate with linguistic simplicity and constrained vocabulary—features that can reflect language learning rather than machine generation. Perplexity measures how surprised a language model is by a sequence of words, with AI tending to produce low perplexity (highly predictable text).
A Stanford HAI write-up of that work emphasizes the practical implication: detectors can be “especially unreliable” for non-native writers, and the mechanism often traces back to perplexity-based scoring and related statistical cues. AI detectors analyze characteristics like sentence structure, word choice, and predictability to estimate whether a text was AI-generated. Stylometric Pattern Matching is also used, analyzing stylistic markers such as average sentence length and vocabulary complexity to identify AI-generated text. Burstiness analyzes the variation in sentence structure, length, and rhythm, with human writing often mixing short and long sentences. Sentence length and sentence structure are important features, as variations in these can help distinguish human writing from AI-generated text.
False positives are not only a student issue. In scholarly contexts, Louie Giray’s paper (archived with full text on ResearchGate) argues that false positives can unfairly accuse scholars of AI plagiarism, disproportionately affecting non-native English speakers and those with distinctive writing styles—creating anxiety, distrust, and professional harm.
False negatives are the mirror image—and they’re amplified by how easy it is to “launder” AI text. The same non-native-bias paper demonstrates bypass techniques: prompting a model to rewrite output in more “literary” language can cause detection rates to drop sharply, because the rewritten text no longer matches the detector’s learned signature. AI detection is probabilistic, meaning it calculates a likelihood rather than providing a definitive identification of AI-generated content.
Detection robustness also degrades under translation, paraphrasing, and deliberate obfuscation. A large evaluation study of detection tools (published in the International Journal for Educational Integrity) concludes that existing detection tools were “neither accurate nor reliable” in their tests and that obfuscation techniques significantly worsened performance. The accuracy of AI detectors can vary based on the algorithms used and the specific characteristics of the text being analyzed.
This is exactly why well-designed detector documentation should be read as risk framing, not marketing copy. Detector24’s own “Known Limitations” include: short texts provide fewer signals; heavily edited AI text may score as human; technical/formulaic writing may resemble AI; and adversarial evasion can succeed. In other words, even the tool developer describes the output as one input into a broader review process—because that is what the current science supports.
Choosing the right AI detector: key criteria and considerations
Selecting the best AI detector for your needs requires careful consideration of several critical factors to ensure reliable and actionable results. First and foremost, the tool should demonstrate a high level of accuracy in identifying ai generated text, minimizing the risk of false positives that could unfairly flag human written content, as well as false negatives that might allow ai generated material to slip through undetected.
It’s also important to evaluate the range of ai models the detector can recognize. With the rapid evolution of language models like ChatGPT, GPT-5, and Gemini, an effective AI detection tool must be capable of identifying content produced by a variety of current and emerging AI systems. For organizations with diverse audiences or international contributors, support for multiple languages is essential, ensuring that detection capabilities extend beyond English and can analyze written content in different linguistic contexts.
A robust ai content detector should provide detailed analysis and clear feedback, helping users understand not just whether content is likely AI generated, but also which sections are most suspect and why. An intuitive user interface is key, making it easy for educators, publishers, and content creators to navigate the tool and interpret results without extensive training.
Finally, the best AI detectors are those that are regularly updated to keep pace with new AI generated writing techniques and shifting text patterns. As AI models and content creation methods evolve, ongoing updates ensure that detection tools remain effective and relevant. By weighing these criteria—accuracy, model coverage, language support, analysis depth, usability, and update frequency—users can select an AI checker that supports their commitment to authentic, human written content and helps them stay ahead in the ongoing challenge of detecting AI generated text.
Policy first: build rules you can enforce—and communicate them early
If your policy is vague, enforcement becomes arbitrary—and AI detectors then become a proxy for policy, which is exactly how “gotcha” dynamics emerge. The safer sequence is: policy first, tooling second. AI detection tools, including Grammarly's AI detector and other tools, should be used as part of a holistic approach to evaluating writing originality, rather than as the sole method of verification. Using multiple tools alongside AI detection tools enhances verification and ensures a comprehensive review process.
For educators, well-regarded guidance emphasizes putting expectations in the syllabus and assignment instructions, and stating what documentation and attribution are required when AI is permitted. The Cornell University Center for Teaching Innovation explicitly recommends clearly communicating policies, clarifying what students must produce themselves, and requiring verification of citations and references (because AI output can be incorrect, and fabricated references are a known failure mode).
For publishers (including scholarly publishing), policy norms are converging around three pillars:
First, humans remain accountable. The International Committee of Medical Journal Editorsstates that AI tools should not be listed as authors; humans are responsible for any submitted material that involved AI; and authors must ensure proper attribution and absence of plagiarism.
Second, disclosure is expected when AI meaningfully affects content. For example, Elsevierdescribes its journal policies as aiming for transparency and guidance for authors and editors in response to increasing AI use.
Third, the workflow must match the risk. Springer Nature’s Nature Portfolio policy states that large language models do not satisfy authorship criteria, expects documentation of LLM use in manuscripts (with some exceptions for copyediting), and warns peer reviewers not to upload manuscripts into generative AI tools due to confidentiality and reliability concerns.
In journalism and public-facing publishing, policy language often sounds different but lands in the same place: transparency, oversight, and editorial responsibility. Reuters states it uses generative AI at times as one of many tools, and discloses when it relies primarily or solely on generative AI for news content. The Associated Press emphasizes that AI output should be treated as “unvetted source material” and reviewed under existing sourcing standards. Council of Europe highlights that adopting AI systems in journalism touches professional practice and audiences, and recommends practical guidance for responsible use across stages of production.
These policies share a design principle worth making explicit: a “high AI-likelihood score” is not automatically a violation unless your policy defines it that way. The violation is usually undisclosed prohibited use, fabrication (facts or sources), or misrepresentation of authorship or process—not merely the statistical signature of the text.
Practical workflows for educators
The simplest way to turn an AI detector into decision support is to treat it like triage: a tool that helps you decide where to look closer, not who to punish. The reason is not just technical uncertainty; it’s governance. Detection scores are a weak foundation for disciplinary action unless they are paired with human review and process-based evidence. AI detectors are designed to detect AI-generated content, supporting academic integrity by identifying text produced by AI and helping educators verify originality.
A defensible educator workflow usually has four layers.
First is an initial scan stage. Many teachers now use detection tools because of workload pressure, and surveys suggest usage is widespread—yet training on appropriate responses is often limited, which increases the chance of inconsistent enforcement. When you use detection as triage, you are explicitly reducing that inconsistency risk: you’re not handing decision authority to the tool. For a comprehensive review, it is also important to use a plagiarism checker alongside AI detection tools to identify both copied and AI-generated content.
Second is human review of flagged work. Here, the goal is not to “spot AI” by vibe. It’s to assess whether the submission aligns with course content, task constraints, and the student’s demonstrated capability. Trent University’s guidance recommends identifying specific “tells” (overly generic responses, missing or nonexistent citations, ideas far outside the course), highlighting the evidence within the paper, and comparing against the student’s prior work as one contextual signal. During this stage, review flagged phrases and highlighted sections to identify parts of the text that may be AI-generated or AI-refined.
Third is process evidence instead of confrontation. This is where disputes either dissolve or explode. The most repeatable approach is: ask the student to show how the work was produced—drafts, notes, source logs, or version history—and ask them to explain key decisions. Trent explicitly recommends a “discovery interview” approach (invite discussion; ask process questions; request notes/drafts; probe familiarity with cited sources). After receiving the AI detection results, it is important to revise flagged sections to better reflect the student's own words and writing style.
The University of Melbourne’s student guidance on AI writing detection frames the detector result as a prompt for further investigation, not an accusation, and lists common follow-ups: explain the argument and sourcing, and provide drafts or notes. It also explicitly notes that the tool may incorrectly identify work and that being asked to explain is not, by itself, an allegation of misconduct.
Fourth is consistent documentation and policy-based outcomes. The International Center for Academic Integrity highlights the fairness problem of using detection as sole basis and quotes vendor-level acknowledgement that AI detection “should not be used as the sole basis for adverse actions” and requires human judgment alongside institutional policy. The editing process is crucial here; after making revisions, it is important to re-scan the text to ensure accuracy and confirm that all flagged issues have been addressed.
Assessment design can reduce both cheating incentives and disputes. The key shift is: include at least one “secure” element that allows direct evidence of individual learning—oral explanation, supervised in-class writing, or practical demonstrations. Tertiary Education Quality and Standards Agency describes “secure assessment” formats that include oral presentations, in-class tasks, and supervised practical demonstrations. Much of the value here is not anti-AI theater; it’s that the assessment captures what detectors cannot: the student’s live grasp of the thinking behind the text.
Practical workflows for publishers and editorial teams
Publishers typically face a different optimization problem than educators. In education, the primary harm is wrongful accusation and distorted learning. In publishing, the primary harm is often shipping unverified content—thin, generic, or inaccurate text that erodes trust, triggers corrections, or creates legal exposure.
A pragmatic publisher workflow usually starts with intake screening. Here AI detection can help you prioritize review, especially when submissions arrive at scale (freelancers, contributors, UGC, or SEO pipelines). Detector24 explicitly positions its model for use cases like “Publishing & Journalism” and recommends combining detection with plagiarism checking, writing-sample comparison, and human judgment—language that maps well to editorial practice. In this stage, using other AI detectors alongside your primary tool can improve accuracy, as different models may catch different patterns. It's also important to analyze the entire text, not just excerpts, to ensure reliable detection of AI-generated content.
For flagged content, the most effective next step is not arguing about authorship—it’s verifying publishworthiness.
That means checking factual claims and source integrity. Both AP standards and Quanta’s editorial policy treat generative AI output as unvetted source material. The operational translation is simple: if a passage looks templated or suspiciously fluent, treat it as a lead, then verify the underlying claims as you would any external source. AI checker tools can detect content from major models, including ChatGPT, Gemini, Claude, and Llama, providing publishers with detailed feedback to distinguish between human and AI writing.
It also means separating AI detection from plagiarism detection. AI detectors estimate “AI-likeness.” Plagiarism checks assess overlap with existing text. They answer different questions. In scholarly publishing, failures frequently show up as fabricated or sloppy references rather than direct copying—one reason multiple publishing guidelines emphasize verifying citations and not relying on AI-generated references.
Assistive tools play a key role in supporting the writing flow, helping publishers and writers refine content for clarity and coherence without disrupting the natural progression of the text. These tools are especially valuable for non-native speakers and for maintaining smooth, readable work when making edits or adding citations. Using AI detection tools to verify originality and promote transparency is now a standard practice for educators, businesses, publishers, and content creators.
The academic publishing ecosystem increasingly reflects that reality. WIRED documents how undisclosed AI use has appeared in peer-reviewed venues, notes there is “no foolproof way” to check for AI use (as compared to plagiarism), and describes publishers responding with disclosure requirements and policy patchworks. Meanwhile, policies like Nature Portfolio’s require human accountability and disclosure, and warn reviewers against uploading manuscripts into AI tools due to confidentiality and error risk.
Once verification is complete, publisher outcomes should be policy-based and consistent. A typical set of outcomes is:
Accept with edits and disclosure when policy allows AI assistance and the piece meets quality and verification standards. This aligns with “disclose when AI is used” practices described by Reuters and editorial policies that label substantial AI involvement.
Request rewrite and sourcing when the piece is generic, poorly evidenced, or contains unverifiable citations—regardless of whether it was AI-generated. This is essentially an editorial quality gate, not an AI gate.
Reject when the submission violates policy—e.g., prohibited ghostwriting, refusal to disclose required AI use, fabricated references, or repeated failure to meet standards.
If you publish on the open web, a separate risk layer is search quality and reputation. Googlehas stated that AI-generated content is not automatically against its guidelines, but using automation “with the primary purpose of manipulating ranking” violates spam policies—especially at scale. Its spam policies define “scaled content abuse” as generating many pages for ranking rather than helping users, including content created via generative AI or through transformations such as translating or synonymizing without adding value. For editorial leaders, the takeaway is not “opt out of AI.” It’s: enforce value, originality, oversight, and accountability—because search ecosystems increasingly penalize low-value scale regardless of whether it was produced by humans, AI, or both.
Interpreting detection results responsibly
Responsible interpretation starts by treating a detection score like a smoke alarm: it can be valuable, but it cannot tell you what caused the smoke, and it can go off for reasons unrelated to fire. Free AI detectors are widely available and can provide instant results, making it easy to quickly check if content may be AI-generated.
That analogy is not rhetorical. Both OpenAI and Detector24 explicitly caution that AI detection is not definitive proof and can fail on short texts, technical/formulaic writing, out-of-distribution content, and post-edited AI text. AI detectors can help assess whether text appears to be AI-generated, but they cannot definitively conclude whether AI was used to produce the text.
Practically, three interpretation heuristics tend to reduce mistakes.
First, prefer passage-level signals over a single global number. Detector24 describes chunk-level scoring and flags high-risk chunks; using this feature (where available) supports a more targeted human review than making a binary decision from an overall score. Some detector tools, such as Grammarly's AI Detector, provide a clear score indicating how much of the text appears to be AI-generated, helping users focus on specific flagged sections. Reviewing phrases and sections that are flagged as AI-generated is important for understanding which parts of the text may require further scrutiny.
Second, check consistency across sections. Mixed authorship is common: a human outline, an AI-generated middle, then a human conclusion; or humans heavily editing AI output. Chunk-by-chunk variation is often more informative than the mean. ChatGPT detectors are specifically designed to identify text generated by models like ChatGPT, analyzing linguistic patterns and stylistic features to detect AI-generated content. Detector tools aim to detect AI generated text while minimizing the risk of misclassifying human written text. Tools like Grammarly's AI Detector are designed to avoid wrongly flagging human-written text, reducing false positives.
Third, treat the “why” as the real question. Perplexity-based detection can judge writing that is simple, templated, or highly predictable as more “AI-like”—which intersects with language learning and certain technical genres. The peer-reviewed work on bias against non-native writers shows how that statistical overlap can become an equity hazard if scores are treated as evidence of misconduct.
A lightweight decision framework can help teams apply scores without overreacting:
Low risk: the score is low or mixed, the writing aligns with expected voice and sources, and there are no “integrity smells.” Proceed with normal grading/editing.
Medium risk: moderate score or a few high-risk chunks, plus signals like generic phrasing, weak sourcing, or style mismatch. Request clarification: drafts, sourcing notes, or author explanation; in publishing, request stronger attribution and fact-check evidence.
High risk: sustained high-risk chunks, obvious fabrication patterns (nonexistent citations, unverifiable claims), or clear policy breach indicators. Trigger deeper review and apply policy-based outcomes—never just an automated rejection or accusation.
The key governance rule is worth stating outright: “high AI-likelihood” is not identical to “rule violation.” A violation exists only relative to a defined policy—what is permitted, what must be disclosed, and what is prohibited. Both Detector24’s disclaimers and the University of Melbourne’s guidance reinforce that detection results should prompt investigation rather than serve as standalone evidence.
Conclusion
AI detection can help protect authenticity, quality, and trust—if it is treated as a signal, not a verdict. AI detection tools are continuously updated to keep pace with evolving AI technologies and improve accuracy. Free AI detection tools are widely available, offering instant results and unlimited checks to verify originality across various platforms. Accurate AI detection tools play a crucial role in research papers and academic publishing, helping to validate authenticity and uphold ethical standards. AI detectors are also increasingly used in cybersecurity to identify AI-written phishing emails or malicious code. Common tools for AI detection include GPTZero, Winston AI, and Turnitin's built-in detectors, which are popular in education and content creation. The modern best practice is not “trust the score.” It is to design a system where the score triggers a structured human workflow: clear policy, transparent expectations, consistent review, process evidence, and layered verification (originality checks, citation verification, fact-checking, and (in education) evidence of learning).
In that system, tools like detector24.ai become what they should be: a force multiplier for responsible decision-making—useful for triage, helpful for pattern-spotting, and explicitly constrained in high-stakes outcomes by due process and human judgment.
Want to learn more?
Explore our other articles and stay up to date with the latest in AI detection and content moderation.
Browse all articles